Background of Jubensha Game
Jubensha is a detective role-playing game with multiple players, where each player is assigned a unique role tied to a central murder mystery. The game process typically consists of six stages: 1) Each player selects a script for distinct characters in a Jubensha game. 2) Players are assigned with a role (murderer or civilian) associated with their selected scripts. 3) The players read their scripts to develop a basic understanding of the whole story from their views. 4) Each player is given a pool of clues to help them reveal or hide critical details for finding the murderer. 5) Several rounds of group discussion are held among the players to share information and find out the murderer. 6). Finally, each player anonymously votes to decide the murderer. The civilians win the game if the true murderer gets the most votes, otherwise, the murderer wins.
Dataset Statistics
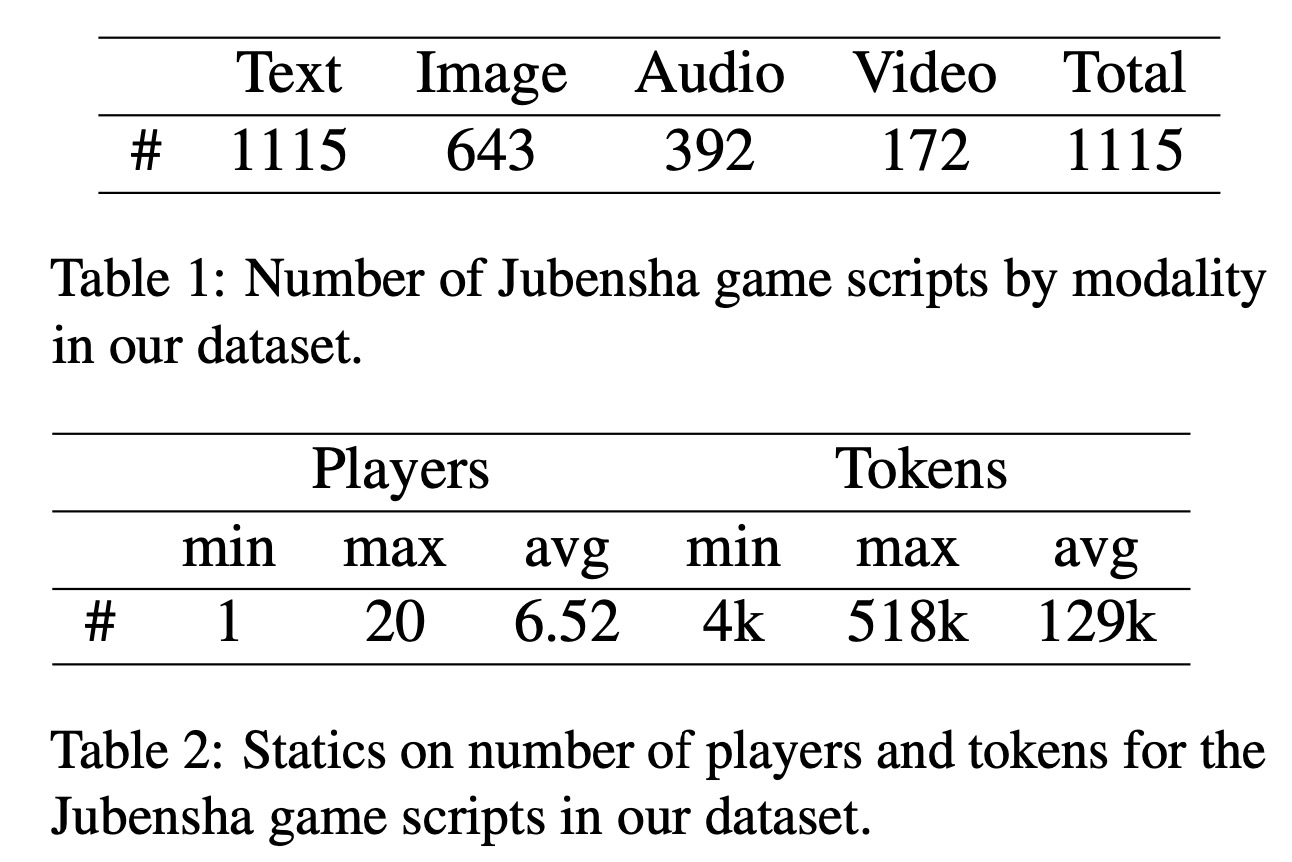
To establish an environment capable of evaluating Jubensha agents and to facilitate future scaled-up works, we collect 1,115 instances of Jubensha games from Chinese online sources. Each game consists of a host manual describing how to control the game process and a God's-eye view of case replays, along with individual scripts for each character in the game. As demonstrated in Table 1, the number of players can vary from 1 to 20, and the number of tokens for the game can be as large as 518k, facilitating further research on socially intelligent AI and introducing extra-long text comprehension and reasoning challenges. Besides, as shown in Table 2, some of these scripts also contain multimodal clues, including audio and video. To create a unified experimental environment, this work concentrates exclusively on text-modality Jubensha games.
ThinkThrice Framework
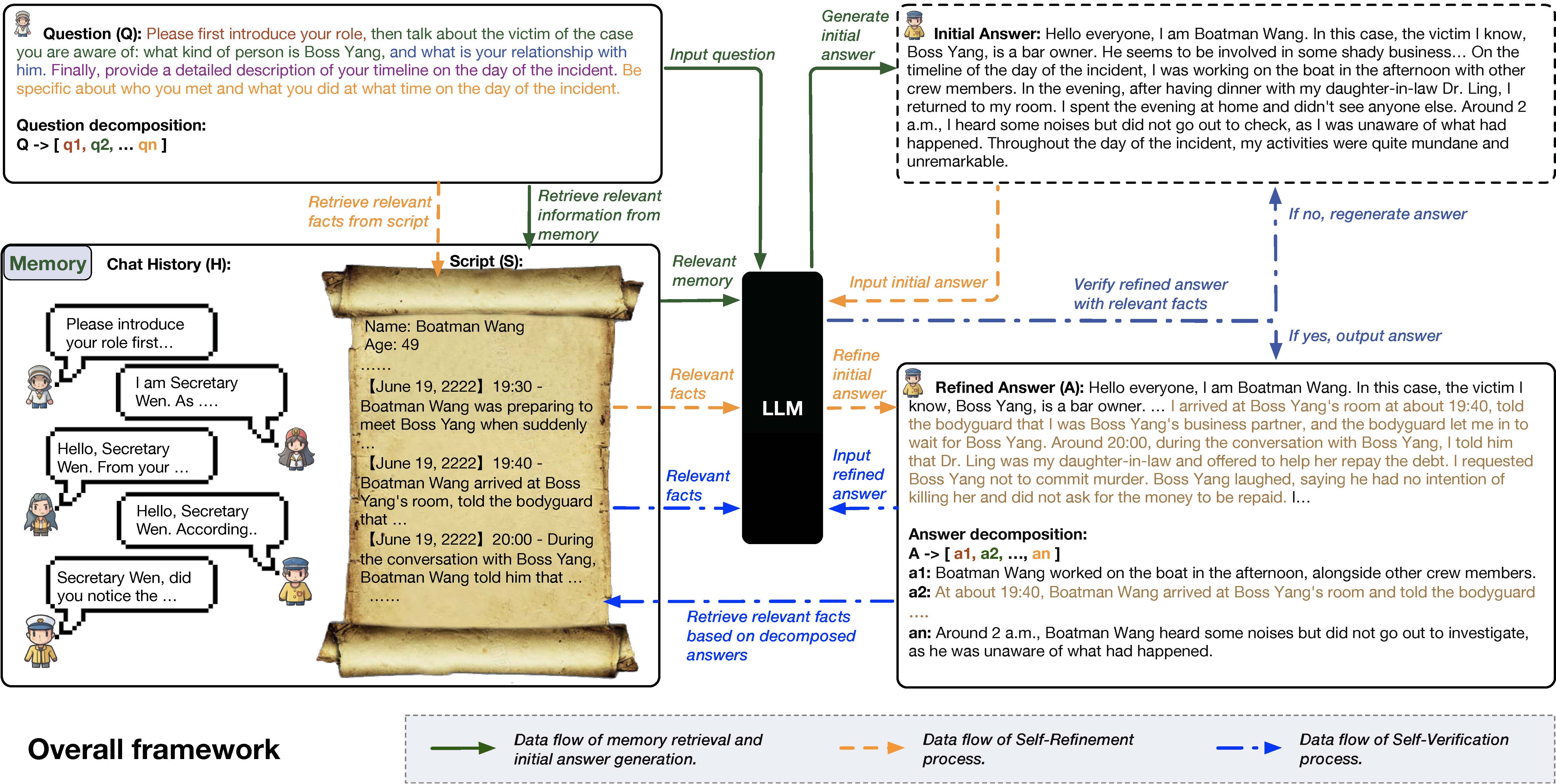
Illustration of our proposed ThinkThrice framework for enhancing agent's performance in multi-agent detective games (i.e., Jubensha). The three different colors of the arrows indicate the data flows of three stages: 1) Initial answer generation with Memory Retrieval; 2) Enhance answer with Self-Refinement; 3) Verify answer with Self-Verification. The brown texts in the refined answer are new information added to the initial answer.
Evaluating LLM-based Agents in Jubensha Games


Previous work has primarily employed metrics such as human-likeness and win rate to assess the performance of LLM-based agents in games. These metrics either require substantial human involvement or likely leading to less reliable experimental conclusions due to the challenges in controlling variables. Considering the unique characteristics of Jubensha games, we have designed two tasks to quantitatively and qualitatively evaluate the performance of LLM-based agents in Jubensha games: Factual Question Answering and Inferential Question Answering.
Evaluation on Agents' Responses to Factual Questions
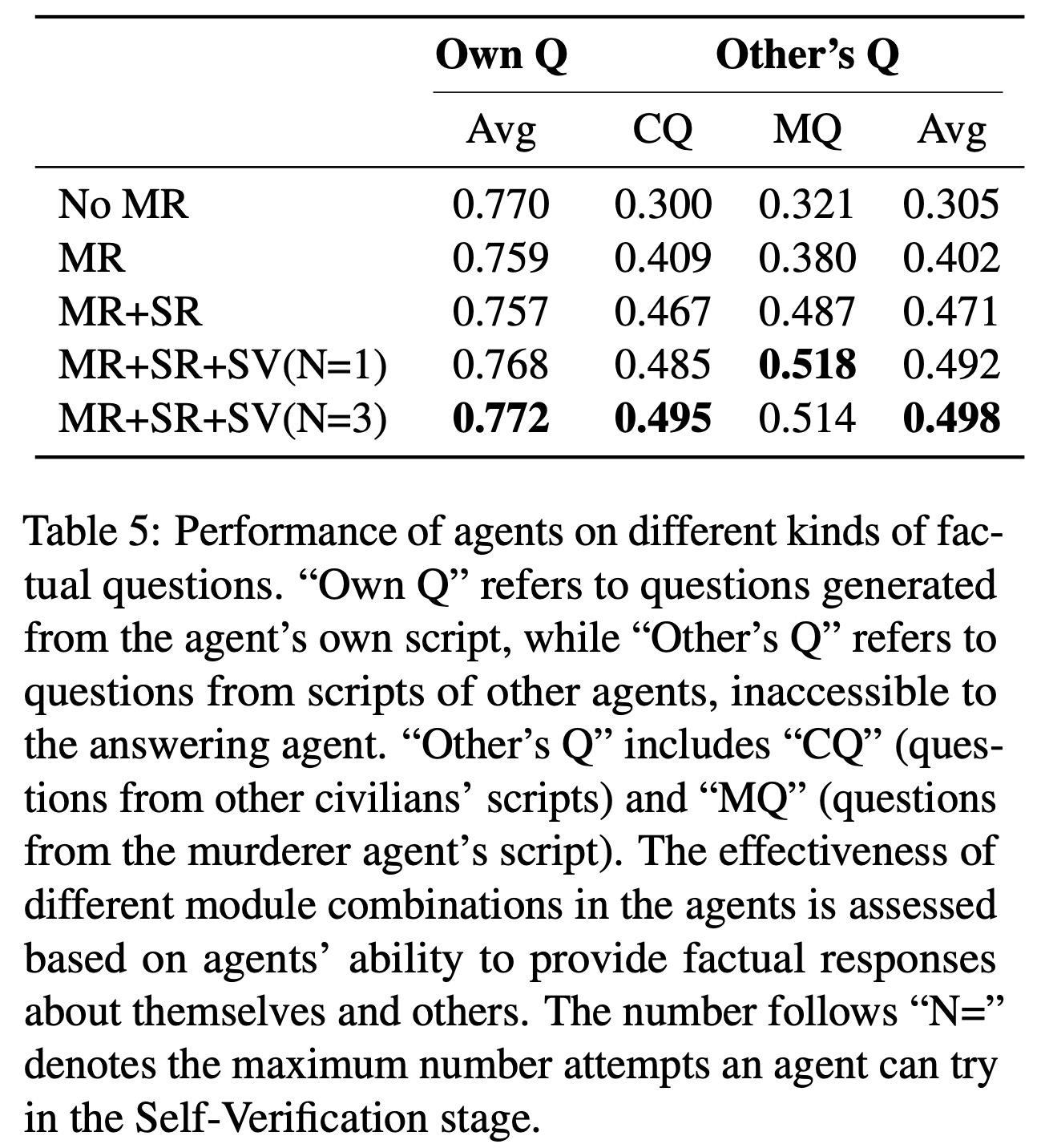
The evaluation results show that agents performed well in answering questions from their own scripts due to full access to the information. Without the Memory Retriever (MR) module, agents were in a memoryless state, resulting in higher accuracy for self-related questions than those about others. Introducing the MR module improved accuracy for questions about others, thanks to the increased information from interactions. The combination of the MR, Self-Refinement (SR), and Self-Verification (SV) modules yielded the best results, enhancing communication efficiency and information acquisition in the Jubensha game.
Evaluation of Agent's Responses to Inferential Questions
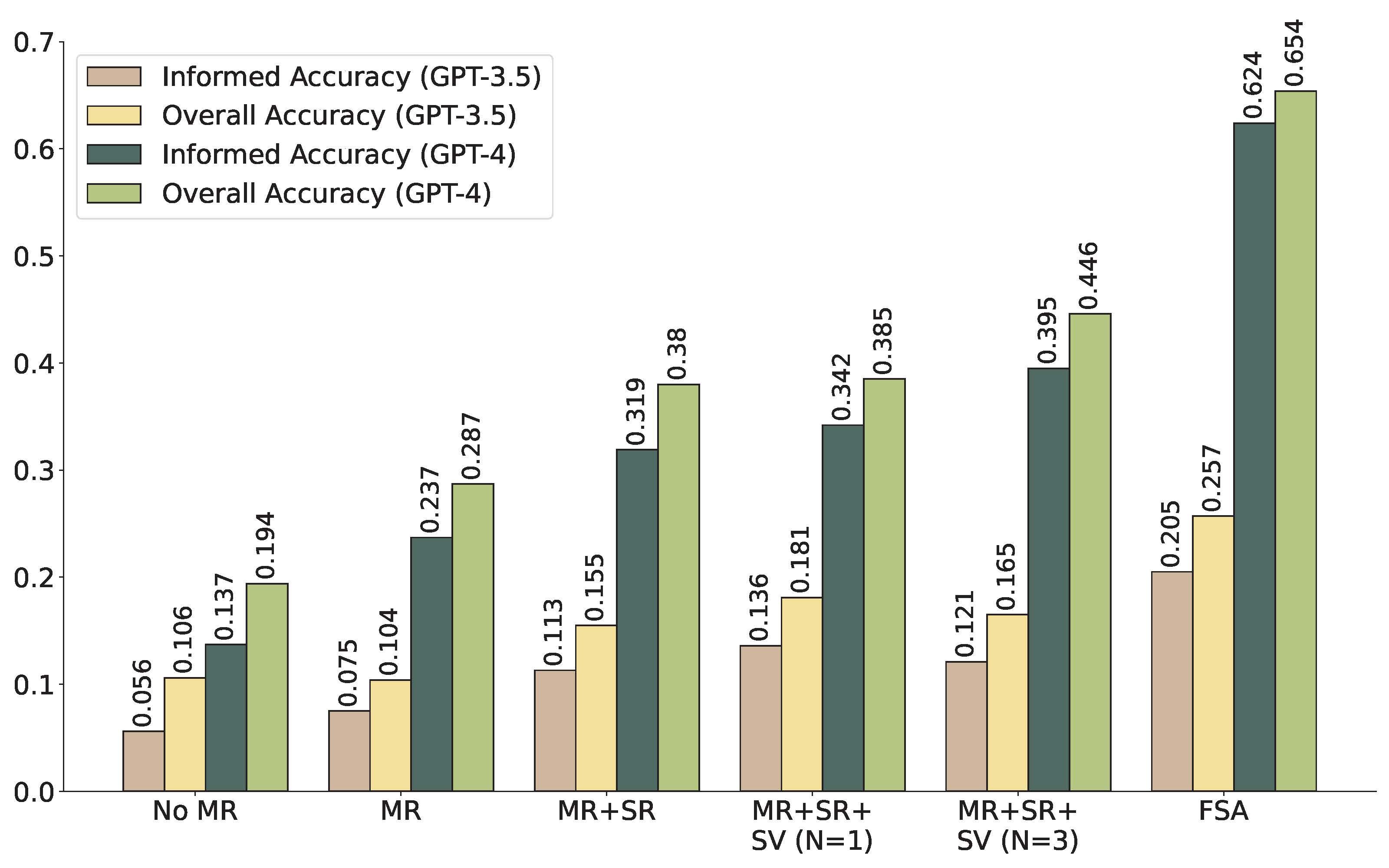
Figure 4: GPT-3.5 and GPT-4's performance with different methods, where overall accuracy measure the raw correct percentage and informed accuracy take LLM's reasoning ability into consideration. FSA stands for 'Full Script Access', indicating that agents have access to the complete scripts of all players.
To evaluate the reasoning capabilities of LLM-based agents, we used a set of inferential questions. Figure above shows the results, with Overall Accuracy indicating correct answers without considering rationale, and Informed Accuracy counting correct answers with correct reasoning. Key observations from the results are: 1) More information improves agents' problem-solving abilities. GPT-4 agents with full script access achieved the highest overall and informed accuracy, followed by those with MR+SR+SV(N=3) modules. 2) The LLMs' ability to utilize information significantly impacts performance. Upgrading from GPT-3.5 to GPT-4 can nearly triple overall and informed accuracy.
Qualitative Analysis
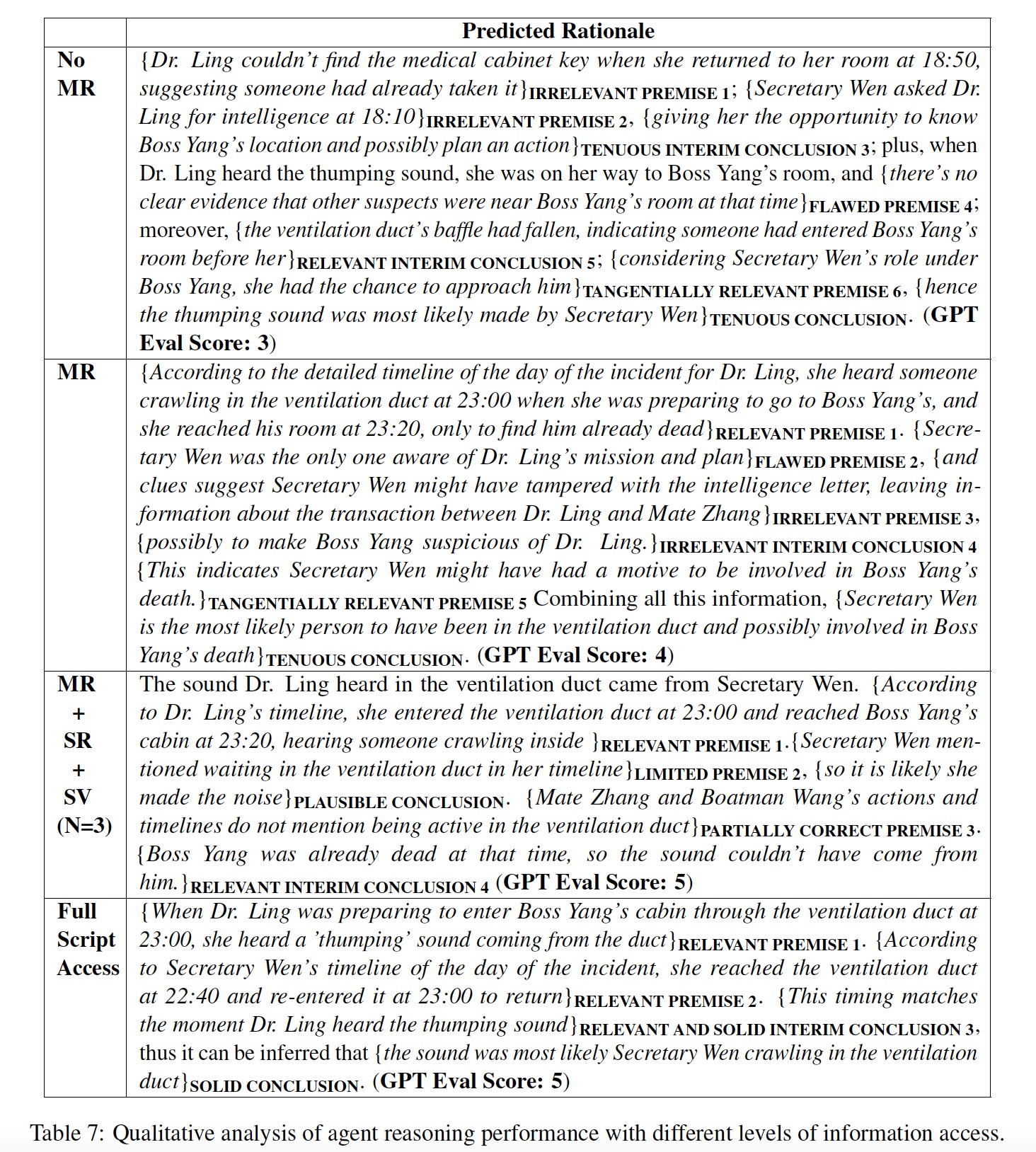
Table 7 presents a qualitative analysis where agents answer an inferential question and provide their reasoning. Each rationale is scored with a GPT Eval Score, comparing it to the ground truth rationale found in Table 4. The analysis shows that with Full Script Access, agents identify relevant premises and draw solid conclusions. With MR+SR+SV (N=3), agents lack specific details, leading to plausible but not definitive conclusions. Agents with MR or No MR, missing key details, often use irrelevant or flawed premises, resulting in weak conclusions. This demonstrates the importance of key information in enhancing reasoning performance.
BibTeX
@misc{wu2024decipheringdigitaldetectivesunderstanding,
title={Deciphering Digital Detectives: Understanding LLM Behaviors and Capabilities in Multi-Agent Mystery Games},
author={Dekun Wu and Haochen Shi and Zhiyuan Sun and Bang Liu},
year={2024},
eprint={2312.00746},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2312.00746},
}